ELK: ElasticSearch + Logstash + Kibana
一、简介
ELK 是一套日志、数据收集,存储,查询与展示的解决方案。
包括三个主要的软件。
1.1 Logstash 具有实时渠道能力的数据收集引擎
可以理解为数据的搬运工,负责数据的采集,并传输给下一级(ElasticSearch)。
从使用端来看,Logstash 的工作流分为 Input,Filter,Output 三个部分。
- input:原始数据的采集,这里可以采集各种数据,如日志,系统日志,调试数据,结构化或非结构化数据。
- filter: 数据过滤器,对 input 采集的数据进行处理,如去除不必要的信息,或者格式重整等。(此项非必须)
- output: 将收集到的数据发送给 ElasticSearch。
Logstash 的三个步骤都提供了丰富的插件,满足多种业务场景的需求。
e.g. Input plugins | Logstash Reference [6.3] | Elastic
1.2 ElasticSearch 实时的分布式搜索和分析引擎
ES 是 ELK 系统的核心,负责数据的存储和搜索。其搜索基于 Lucene 实现,在使用中,可以 lucene 的搜索语法。 其主要特点是分布式,可以管理多个集群。 可对外提供 RESTful 风格的接口。
官方文档 : Elasticsearch: RESTful, Distributed Search & Analytics | Elastic
1.3 Kibana 数据的前端展示和可视化查询
Kibana 为数据的数据的查询和展示提供了方便的操作接口,并有丰富的可视化组件、看板等。能够跟直观地查看数据。
ELK 基本结构图
这里的所有的内容都是分布式的。
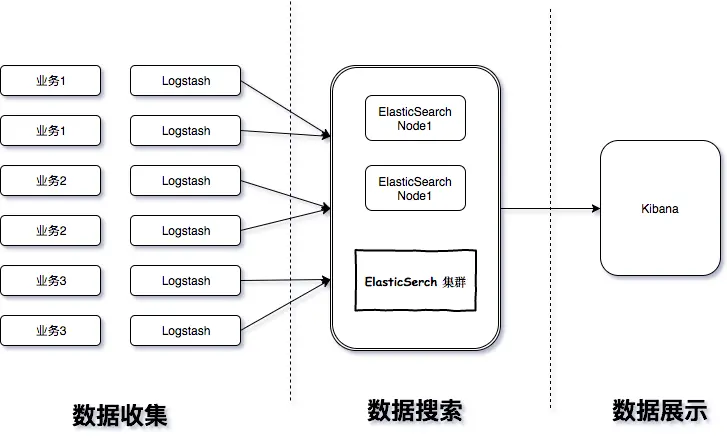
参考阅读:
集中式日志系统 ELK 协议栈详解
二、ElasticSearch
2.1 背景知识 - 搜索框架
1、Lucene
Apache下面的一个开源项目,高性能的、可扩展的工具库,提供搜索的基本架构; 如果开发人员需用使用的话,需用自己进行开发,成本比较大,但是性能高。
2、solr
Solr基于Lucene的全文搜索框架,提供了比Lucene更为丰富的功能, 同时实现了可配置、可扩展并对查询性能进行了优化 建立索引时,搜索效率下降,实时索引搜索效率不高 数据量的增加,Solr的搜索效率会变得更低,适合小的搜索应用,对应java客户端的是solrj。
3、elasticSearch
基于Lucene的搜索框架, 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口 上手容易,拓展节点方便,可用于存储和检索海量数据,接近实时搜索,海量数据量增加,搜索响应性能几乎不受影响; 分布式搜索框架,自动发现节点,副本机制,保障可用性。 主要特点:对分布式支持很好。
2.2 ElasticSearch 概念理解
2.2.1 Index - Type - Document - Field
在ElasticSearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中, 索引名称必须是小写。
类比于关系型数据库,其关系如下
| 存储类型 | 数据库-索引 | 表-类型 | 数据行-文档 | 数据列-字段 |
|---|---|---|---|---|
| Relational DB | Database | Table | Row | Column |
| Elasticsearch | Index | Type | Document | Field |
以上类比可以方便地理解 ES 中的概念,但还是有区别的。
主要区别是:
关系型数据库的存储是基于表的,扁平化的存储,如一个 Person 对象中,有 ContactInfo 这个对象,ContactInfo 包含多个字段,如地址,邮编,邮箱,电话等等。
在关系型数据库中,通常会使用两张表来存储 Person 和 ContactInfo 信息,之间通过 ID 关联。
而在 ES 中,支持非结构化存储,一个 Person 对象的数据(在关系型数据库中称为一条记录,或者一行,在 ES 中称为一条文档),就是这个完整的记录,不需要另外一个 ContactInfo 表,具体的,ES 使用 json 表示这样一条数据(一个文档)。
e.g.
{ "name":"zhangsan", "contactInfo": { "Email":"abx123@xyz.com", }}2.2.2 分片 shards
问题:数据量特大,没有足够大的硬盘空间来一次性存储,且一次性搜索那么多的数据,响应跟不上。
ES 提供把数据进行分片存储,这样方便进行拓展和提高吞吐。
2.2.3. 副本 replicas
分片的拷贝,当主分片不可用的时候,副本就充当主分片进行使用。
Elasticsearch 中的每个索引分配5个主分片和1个副本(1个副本:5个分片的拷贝),即10个分片。
2.3 ElasticSearch 基础操作
2.3.1 curl
curl 指令:模拟 http 请求
curl-X 指定http的请求方法 有HEAD GET POST PUT DELETE-d 指定要传输的数据-H 指定http请求头信息ElasticSearch 中使用 curl 的格式:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'- 新增索引
curl -XPUT ‘localhost:9201/blog_test?pretty’
curl -XPUT ‘localhost:9201/blog?pretty’
以上指令是新建一个 blog_test 和 blog 的索引,并将返回结构美化输出(格式化一下)。
- 删除索引
curl -XDELETE ‘localhost:9200/blog_test?pretty’
删除 blog_test 这条索引。
- 新增一条记录(Document),并指定为 article 类型(Type),ID为1
curl -XPUT -H "Content-Type: application/json" 'localhost:9201/blog/article/1?pretty' -d '{ "title" : "Blog Title", "content" : "Blog Content", "Article" : "Xiaoming"}'新增一条记录,使用 -H 指定 HTTP 请求头,-d 指定要传输的数据。
这句的意思是:在 blog 索引下,增加一条类型为 article 的数据,改数据的 id 为 1。
- ID查询记录
curl -XGET ‘localhost:9200/blog/article/1’ curl -XGET ‘localhost:9200/blog/article/1?pretty’(美化推荐)
查询 blog 索引下,article 类型中,id 为 1 的文档。
- 搜索
curl -XGET 'http://localhost:9201/blog/article/_search?q=title:Title'在 blog 索引的 article 类型中,搜索 title 字段匹配 “Title” 的文档。
q 表示查询,后面是 lucene 查询语句。
2.3.2 其它查询和操作方式
除了使用 curl 命令进行操作,ES 还提供了多种查询接口。
kibana 的 DevTools 面板中,使用的其实就是简化的 curl 命令。
其它查询方式如 C# 也是支持的
var client = new ElasticClient();var searchResponse = client.Search<Tweet>(s => s .Index("social-*") .Query(q => q .Match(m => m .Field(f => f.Message) .Query("myProduct") ) ) .Aggregations(a => a .Terms("top_10_states", t => t .Field(f => f.State) .Size(10) ) ));更多内容可以看这里:
Elasticsearch Clients | Elastic
2.4 search搜索语句之结构化查询语句DSL
DSL 是 ES 里面可以完成相当复杂查询的语句。
- 什么是 query DSL
1、Domain Specific Language 领域特定语言
2、Elasticsearch提供了完整的查询DSL,基于JSON定义查询
3、用于构造复杂的查询语句
- curl查询(空格处理不当,会出问题)
curl -XPOST -H "Content-Type: application/json" 'http://localhost:9201/blog/article/_search' -d '{ "query" : { "term" : { "title" : "elk" } }}'# term 关键字: 指定字段查询与上面看到的不同,这里采用 POST 请求,给 _search 路由发送查询请求,请求 body 使用的就是 DSL 查询语句。整个查询语句是一个 json 语句。
可以在 kibana 的 DevTools 面板里面体验。
DSL 查询语句分两部分,第一个是查询,以 query 关键字开头,第二个是过滤,以 filter 关键字开头。
query 指定查询的内容,其会参与查询结果的评分,评分多则表示匹配度高,查询结果靠前。
filter 是对 query 的查询结果进行过滤,但不参与评分。
官方文档:Query and filter context | Elasticsearch Reference [6.3] | Elastic
在开发 ES 调试时,建议使用 postman 工具。post 方式提交,增加 http 头信息。body 里面选 row 格式,粘贴对应的 dsl 即可。
- bool 查询示例
{ "query": { "bool": { "must": [ { "match": { "title": "elk" } } ], "must_not": [ { "match": { "title": "小D" } } ] } }}- filter 查询示例
filter 查询(filtered语法已经在5.0版本后移除了,在2.0时候标记过期,改用filter ) 参考地址:https://www.elastic.co/guide/en/elasticsearch/reference/5.0/query-dsl-filtered-query.html
{ "query": { "bool": { "filter": { "range": { "PV": { "gt": 15 } } }, "must": { "match": { "title": "ELK" } } } }}总结:
1、大部分filter的速度快于query的速度
2、filter不会计算相关度得分,且结果会有缓存,效率高
3、全文搜索、评分排序,使用query
4、是非过滤,精确匹配,使用filter
三、Kibana
基础操作文档:
Kibana User Guide [6.3] | Elastic
Kibana 用户手册 | Elastic
3.1 创建索引表达式(Define Index Pattern)
在 Management 面板中,新建一个索引匹配项,可以使用*统配符,去匹配ES中的一个或多个索引(如果没有匹配,无法点击下一步), 后续查询操作都是基于这个索引项的匹配去做。
可以理解为一个索引组。如,有一个 mylog 的索引,实际情况下,通常是每天建立一个新的索引,即
mylog-2018-08-01,mylog-2018-08-02,…
如果我们要对 mylog 相关的内容进行后续的查询,聚合分析,数据展示,就需要建立一个 mylog-* 的索引匹配/索引组。
3.2 discover 面板发现数据,原始查询
建立索引匹配之后,就可以在 discover 面板中看到相应的项,选择之后,就可以进行原始数据的查询了。
可以指定时间进行查询。 可以使显示的字段。 查询索引的数据,是使用lucence语法进行查询。
3.3 可视化
可以在 Visualize 进行数据可以的配置。
首先选择要进行可视化的索引匹配/索引组,然后建立一个可视化组件。
具体方法,可以看文档:
Kibana 用户手册 | Elastic
Dashboard 提供了一个可视化面板聚合展示的功能,可以展示多种多样的数据,日常的数据检测主要就是看这里了。
更多内容,看文档咯。
官方文档目录:
- 总文档目录 Elastic Stack and Product Documentation | Elastic
- 简体中文文档目录(2.x 版本,内容偏旧) 简体中文 | Elastic
- Kibana 简体中文用户手册 Kibana 用户手册 | Elastic
- Elastic中文社区
参考资料
原文链接: https://blog.jgrass.cc/posts/logstash-es-kibana-start/
本作品采用 「署名 4.0 国际」 许可协议进行许可,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。